关于全球数以百万计的网站运营者与网民来说,本周的周二,注定又是一个难忘的一天。
如咱们所见(在
新闻上
所见),在这一天的短短数小时内,包含X(原Twitter)、ChatGPT、Spotify等(海外)常用巨子服务在内,海外互联网范畴简直堕入瘫痪。不管改写多少次,映入眼前的都是相同的“InternalServerError”报错页面。但后来总结来看,这并不是一次外部进犯导致的人为事端,而是一场由Cloudflare内部引发的全球性技能毛病。工作的原因源于一次再惯例不过的例行晋级。正常状况下,每天,Cloudflare都会为其Bot办理模块生成一个“特征文件”,用来协助辨认歹意机器人。这本是一项一般的后台流程,但当天文件的生成程序因为数据库权限调整呈现反常,意外重复写入部分内容,文件体积因而比平常大了整整一倍。这看上去或许仅仅一个细微的问题,但关于体系层面来说,却足以成为完全击穿署理层的导火线。
依照Cloudflare的说法,Cloudflare的网络结构决议了这种配置文件需求在全球一切边际节点同步。也便是说,一旦生成,它会被敏捷推送至遍及国际的数千台服务器。而当这些节点接收到反常文件后,负责处理悉数HTTP恳求的中心程序没能成功解析,直接溃散。因为文件同步速度极快,多个国家、多个区域的节点简直在附近时刻呈现相同的毛病,也就形成了用户看到的“全球同步掉线”的古怪场景。
更让状况复杂的,是体系还会每隔几分钟主动查看更新。这意味着,旧的正确文件偶然会让部分节点时刻短康复,但很快又会被新的过错文件掩盖,再次宕机。自然而然的,外界其时看到的也便是网站“康复—再报错—再康复”的循环。
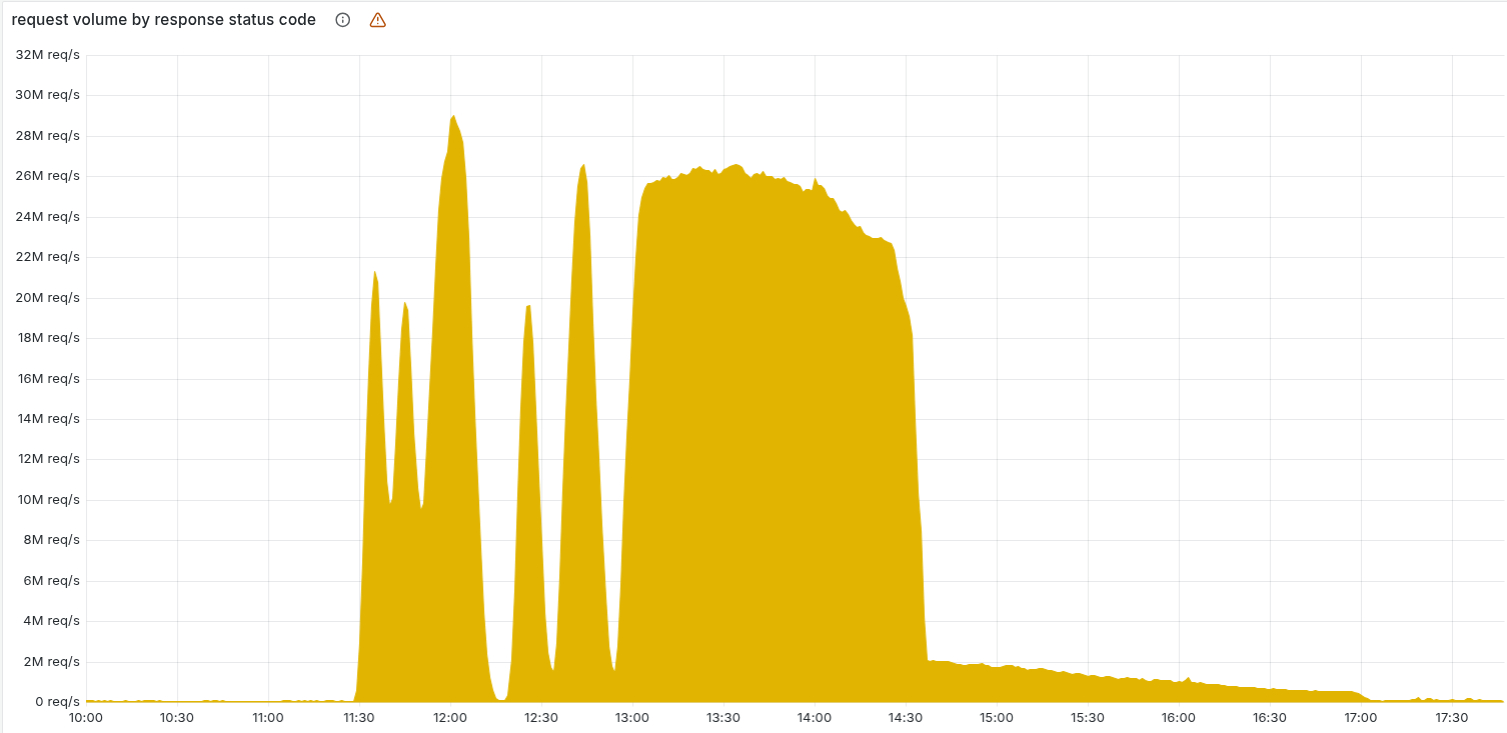
这一剧本直到工程师们终究追寻到特征文件自身,并暂停了过错文件的更新,状况才逐步稳定下来。当天稍晚时刻,Cloudflare开端向全球节点从头推送正常版别,各地的署理服务连续康复,过错量在短时刻内敏捷下降。不久后,Cloudflare宣告一切体系回到正常状况,但这次宕机的影响现已被记载为近期互联网根底设施事端中“规划最为稀有的之一”。
作为全球互联网根底设施的重要组成部分,Cloudflare此次大规划宕机敏捷引发了各界的重视和反应。而事发当日,Cloudflare盘前股价也一度跌落超越2%。Cloudflare首席技能官Dane Knecht随后在X上揭露致歉,供认网络在当天呈现严重问题,“孤负了依靠咱们的客户和整个互联网···”但回到事端自身,不难发现,它之所以引发如此激烈的评论,很大程度上是因为于此提醒出的是一个越来越需求回应的问题。
当下,越来越多的渠道将功能优化、安全防护、拜访操控等要害才能托付给职业巨子——以Cloudflare自身为例,其承载着全球大约五分之一的互联网流量。在这样的结构下,一旦中心署理层呈现毛病,它所依靠的多个产品链路会一起失效,而这儿承载的不计其数家服务也会在极短时刻内同步感受到冲击。
而这也正像咱们在上个月前刚看到的那样。彼时,互联网的另一大根底构成——AWS也阅历了一次
相同等级
的中止。依据监测渠道数据,其时共有超越两千家服务受到影响,累计超越八百万条用户报错被记载。此次Cloudflare的事端,则再次让““互联网的命运,过度依附于少量几家巨子”这个问题放置在了人们的面前。当然,在这个面前的是这样的一组数据,就云核算范畴而言,全球前三家巨子(AWS、微软Azure和谷歌云)掌控了超越其间近七成的根底设施。
当然,也正是根据这一点,不难意料,不管是AWS仍是Cloudflare,在此之后,咱们明显还会再度阅历相同的阅历。但,当这些这些毛病越来越多的产生时,这些问题也注定会随之变得越来越无法逃避。